Presentation
The disadvantage of cloud solutions lies in the fact that the processing of data transferred to the cloud can only be carried out if the data is unencrypted, making it possible for an unauthorised third-party to access the data. The objective of our technology called HbHAI (for Hash-based Homomorphic Artificial Intelligence) we have developped and we are working on is to enable data analysis and artificial intelligence processing (Machine learning, big data, deep learning, database query) to be carried out directly on the encrypted versions of the data while guaranteeing that the results are identical to those that would be obtained on the unencrypted data.
Now mathematical design and security proof have been completed. PoCs have been finalized. Deep evaluation by data scientists is now completed.
Parameters, Security and Performances
The latest tests of our PoC confirm the mathematical theory and information mentioned above.
We have been able to implement a k-means algorithm directly on encrypted data:
- Number of individuals 100,000
- Number of characteristics per individual: 50,000
- 256-bit encryption key
We compared classification without and with encryption using Rand’s R index. We systematically obtain the value R = 1, which indicates that encryption preserves perfect classification.
Homomorphic data analysis works with 128-, 256-, 392- or 512-bit secret keys.
The security of this encryption technique has been evaluated according several scenarios, under the assumption that the attacker knows the encryption principle (only the secret key is unknown)
- the attacker has a large number of encrypted data vectors (encrypted with the same or with different keys)
- The attacker knows the nature of the various characteristics describing an individual.
In all cases, cryptographic security has been proven to be at least equal to current encryption standards.
- At best, the key can be found by brute force only. The knowledge of plaintext/encrypted pairs does not provide any usable knowledge.
- Reconstructing one or more plaintext data vectors from their encrypted versions has a double exponential complexity (reidentification).
The GDPR compliance analysis and validation was finalized by our DPO/ethical officer. In particular, he pointed out that another application of this homomorphic data analysis technique is the ultra-fast search of data in an encrypted database or in encrypted texts. The very first tests confirm this possibility for an exact search (same text). It also seems possible to search for similar or nearby is also possible, and will give rise to verification PoCs very soon.
We have extended our technology to all supervised and deep learning algorithms, the main theoretical bottleneck having been successfully overcome. We are also aiming to implement our algorithms on hardware (SoC).
IP Protection and Industrialization
We are currently working on the industrialization of HbHAI. Industrial deployment is envisaged as follows
- Implementation in an HSM containing the keys and the encryption logic (the HSM contains strong anti-tampering mechanisms).
- Deployment of the HSM on behalf of the customer in a secure zone, in two possible use-cases
- the HSM is on the customer’s premises, and once protected (black traffic) data is transferred to the cloud provider for ML/BD/DL processing (Figure 1)
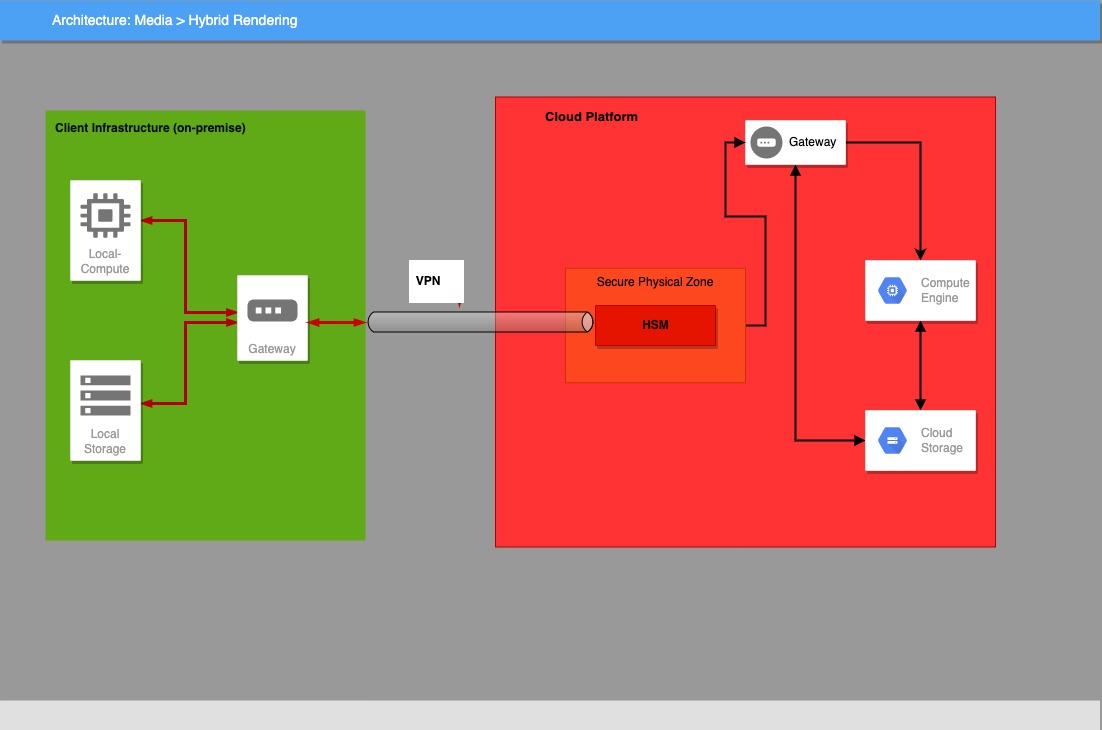
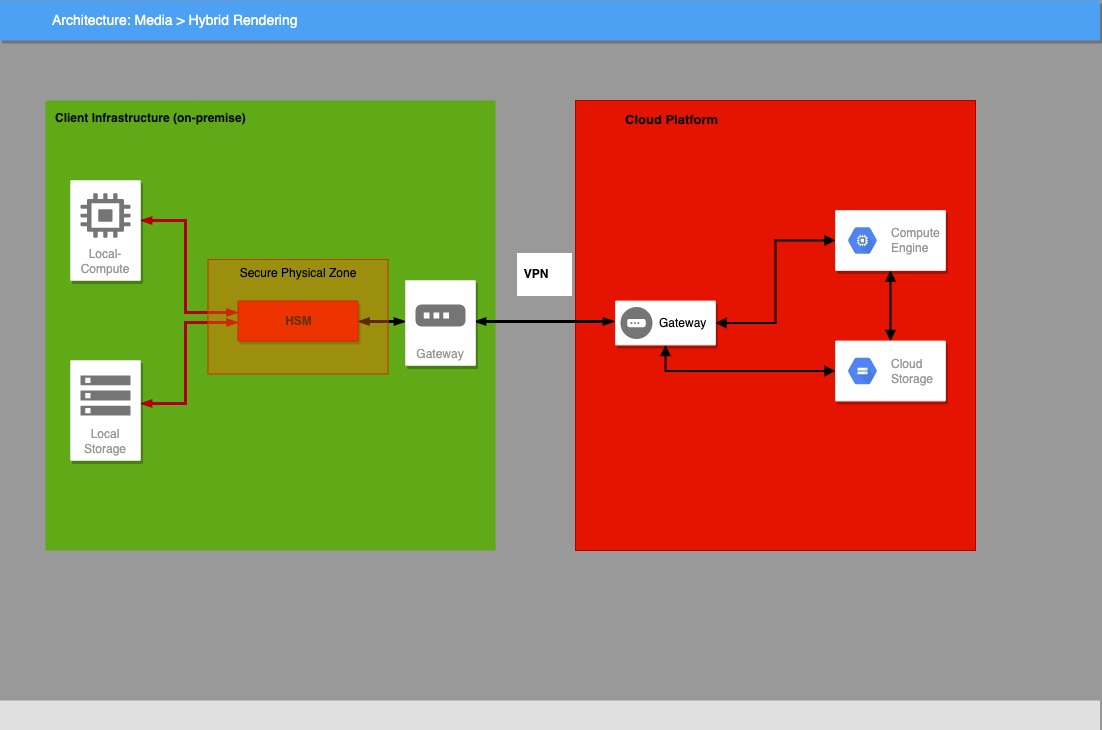 - the HSM is deployed directly at the cloud provider in a secure zone under customer’s control. The security of this scenario relies on the security and
trust of the data encapsulation mechanism (SSH, TLS) used to send data to the HSM (figure 2).
- the HSM is deployed directly at the cloud provider in a secure zone under customer’s control. The security of this scenario relies on the security and
trust of the data encapsulation mechanism (SSH, TLS) used to send data to the HSM (figure 2).
In parallel with this R&D and industrialization work, we are studying the best way to protect the intellectual property of our technology (patentable, copyrightable or managing as trade secrets). The choice we make will determine whether we publish all or part of our technology. We are interested in finding industrial collaborations or technology transfer.
Evaluation for Deep Learning
We have just succeeded to train neural networks on data encrypted with HDAS. For sake of validation, we have considered the Fashion MNIST dataset which is a drop-in replacement of the MNIST dataset. More exactly it is a dataset of Zalando’s article images consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes.
In order to test HAI on Neural Network, we apply the Tensorflow/Keras deep learning technique proposed by Aurélien Géron in his book ``Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow’’ (3rd edition, chapter 10, Section Implementing MLPs with Keras). We did not tune the proposed algorithm with specific parameters yet. We just applied the algorithm on the HDAS-encrypted Fashion-MNIST dataset with the same parameters.
Here are the main results:
- Both the training and validation steps are successful with performances results almost similar to those on the original unencrypted dataset (accuracy of 0.8854 versus 0.8188). The next step will focus on fine-tuning the Neural Network hyperparameters and there is no doubt that we will fully equal the best performance results known to date.
- The computing time is the same (no overhead due to data encryption).
- Learning curves are similar (unencrypted data [left] and HAI encrypted data [right]):
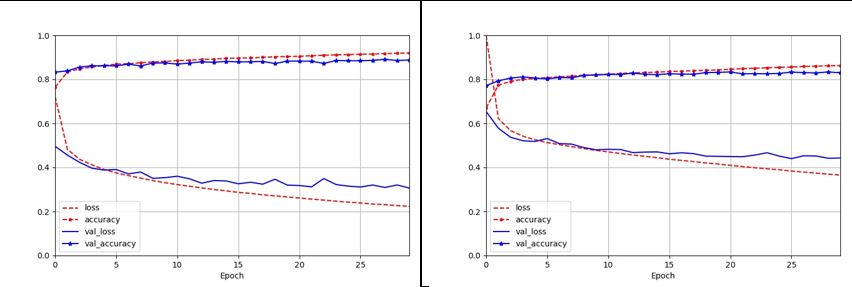
- Prediction performances are the same.
Mathematical Formalization
Thanks to external collaboration, we have now a formalization our new approach by means of a new class of secure hash function with new security requirements.
The industrial application of HAI is called HbHAI (Hash-based Homomorphic Artificial Intelligence).
This new class of key-dependent hash functions naturally preserves the similarity properties, most AI algorithms rely on. Among their many features, HbHAI techniques can reduce data size with a compression ratio of at least 3. While strongly preserving data security and confidentiality, this reduces storage space and computation time for native, “ready-to-use” AI algorithms.
This formalization has been presented at the 2025 International Conference of the AI Revolution: Research, Ethics and Society (AIR-RES 2025) in April in Las Vegas. The corresponding paper is about to be published by Springer Nature.
HbHAI Protected Datasets
We publish here two datasets for public analysis. We have presented them at the CCSE-ICAI 2025 Conference in Las Vegas (Jaagup Sepp’s paper. The paper is about to be published by Springer Nature.
In order to confirm our own inital analysis, we provided these datasets for external analysis in non public preview. This independent technical evaluation of HbHAI techniques has been presented at CyberWiseCon 2025 in Vilnius. The corresponding paper is available on ArXiv. This paper confirms all of our claims regarding HbHAI.
The two datasets are
- Cybersecurity data. The compression rate is delta = 3. Only the HbHAI protected version is provided. Dataset1.zip (one single ZIP file containing training and validation data in ZIP and TGZ formats). The training set contains 4000 objects (2000 per class). The validation set contains objects (200 per class). Each object is defined by 49 955 features.
- Cybersecurity data. The compression rate is delta = 10. Only the HbHAI protected version is provided. Dataset1-delta10.tgz (one single TGZ file containing training and validation data). The training set contains 2000 objects (1000 per class). The validation set contains 200 objects (100 per class). Each object is defined by 49 955 features.
- Zalando Fashion MNIST protected with HbHAI
- Compression rate Delta = 3. Delta-3.zip (one single ZIP file containing training and validation data in GZ format).
- Compression rate Delta = 6. Delta-6.zip (one single ZIP file containing training and validation data
in GZ format).